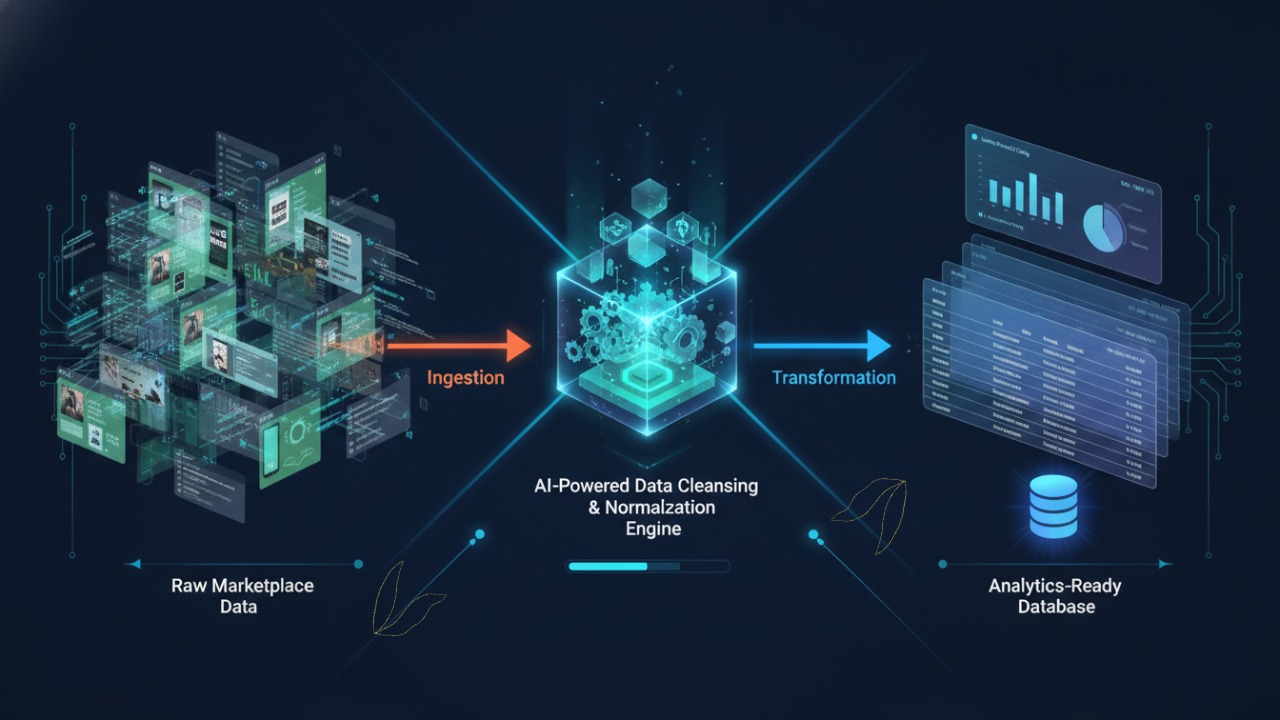
Artificial Intelligence (AI) systems are only as powerful as the data they learn from. Modern AI models—especially large language models (LLMs)—depend heavily on massive datasets that include millions of news articles, tens of millions of long-form texts, and hundreds of millions of user reviews.
Platforms like AI Training Data Use Cases and specialized providers such as Crawl Feeds AI Training Data make it easier to access and structure such data for scalable AI development.
In this article, we explore key dataset types, including:
- 5M+ news datasets
- 10M+ article corpora
- 150M+ review datasets
along with their use cases and how to leverage them effectively.
The Importance of Large-Scale Datasets in AI
AI models require vast amounts of diverse data to generalize effectively. Web-scale datasets are especially critical because:
- They capture real-world language usage
- They provide context across domains
- They enable pretraining and fine-tuning
In fact, modern AI systems rely heavily on web-scraped data pipelines that convert unstructured content into structured formats like CSV or JSON for training purposes
1. News Datasets (5M+ Articles)
Large news datasets aggregate millions of articles from global publishers.
You can explore practical implementations here:
AI Training Data Use Cases
Key Features
- Multi-domain coverage (politics, tech, finance, health)
- Time-series data for trend tracking
- Real-world reporting and narratives
Use Cases
• News Summarization
Train models to generate short summaries from long articles.
• Fake News Detection
Identify misinformation patterns using labeled datasets.
• Trend & Market Monitoring
Organizations use news datasets for real-time intelligence and forecasting.
• Topic Classification
Automatically categorize articles into topics like business, sports, etc.
2. Article Datasets (10M+ Articles)
Massive article corpora include blogs, research papers, and editorial content.
Example dataset:
Medium Articles Dataset
Full Medium Dataset Collection
Key Features
- Long-form, high-quality text
- Rich semantic structure
- Metadata (author, tags, engagement metrics)
Use Cases
• Training Large Language Models
These datasets are ideal for pretraining models like GPT-style architectures.
• Semantic Search Engines
Build search systems that understand meaning, not just keywords.
• Content Recommendation Systems
Recommend relevant articles based on user interests.
• Knowledge Extraction
Extract structured knowledge to build knowledge graphs.
3. Review Datasets (150M+ Reviews)
User-generated reviews are among the richest sources of sentiment data.
Example dataset:
Trustpilot Reviews Dataset
Key Features
- Sentiment-rich text (positive, negative, neutral)
- Product/service-specific insights
- Large-scale user opinions
Use Cases
• Sentiment Analysis
Train models to classify emotions and opinions.
• Recommendation Systems
Use reviews to improve personalization engines.
• Customer Feedback Analysis
Identify pain points and product strengths.
• Aspect-Based Sentiment Analysis
Understand opinions on specific features (e.g., price, quality).
Crawl Feeds Dataset Ecosystem
Platforms like CrawlFeeds provide structured datasets across multiple domains.
Explore directly:
- AI Training Data Use Cases (CrawlFeeds)
- Market Research Use Cases
- Trustpilot Reviews Dataset
- Medium Dataset Collection
What Makes These Datasets Valuable?
- Access to billions of structured records
- Clean formats (CSV, JSON, Excel)
- Coverage across industries like ecommerce, media, and reviews
- Ready-to-use for machine learning pipelines
These datasets support applications such as sentiment analysis, recommendation systems, and trend forecasting
Market Research & Business Intelligence
AI datasets are not just for model training—they are heavily used in market research.
Learn more here:
Market Research Use Cases
Applications
- Competitor analysis
- Pricing intelligence
- Consumer sentiment tracking
- Demand forecasting
Businesses leverage structured datasets to turn raw web data into actionable insights and strategic decision
How to Use These Datasets in AI Pipelines
Step 1: Data Collection
- Use prebuilt datasets or web scraping tools
- Ensure data is relevant to your domain
Step 2: Data Cleaning
- Remove duplicates and noise
- Normalize formats
Step 3: Data Structuring
- Convert into training-ready formats (JSON, CSV)
Step 4: Model Training
- Pretrain on large datasets
- Fine-tune on domain-specific subsets
Step 5: Evaluation & Deployment
- Test performance
- Deploy in real-world applications
Combining Datasets for Better AI
The real power comes from combining datasets:
| Combination | Benefit |
|---|---|
| News + Reviews | Understand public reaction to events |
| Articles + Reviews | Combine context + sentiment |
| News + Articles | Improve general knowledge models |
Challenges of Large AI Datasets
• Data Quality
Large datasets often contain noise and inconsistencies.
• Bias
News and reviews may reflect cultural or platform bias.
• Privacy & Compliance
Web-scraped datasets may include sensitive information if not filtered properly.
• Infrastructure Costs
Handling millions of records requires scalable storage and compute.
Conclusion
Datasets such as:
- 5M+ news articles
- 10M+ long-form articles
- 150M+ reviews
are the backbone of modern AI systems. Platforms like CrawlFeeds simplify access to these datasets, enabling developers and businesses to build intelligent, data-driven solutions.
Whether you're building a chatbot, recommendation engine, or market intelligence platform, leveraging large-scale structured datasets is the key to unlocking AI’s full potential.
Looking for a dataset?
Browse hundreds of pre-built datasets from CrawlFeeds — ecommerce, reviews, fashion, news, and more. Free samples on every dataset.
Browse datasets Custom data request