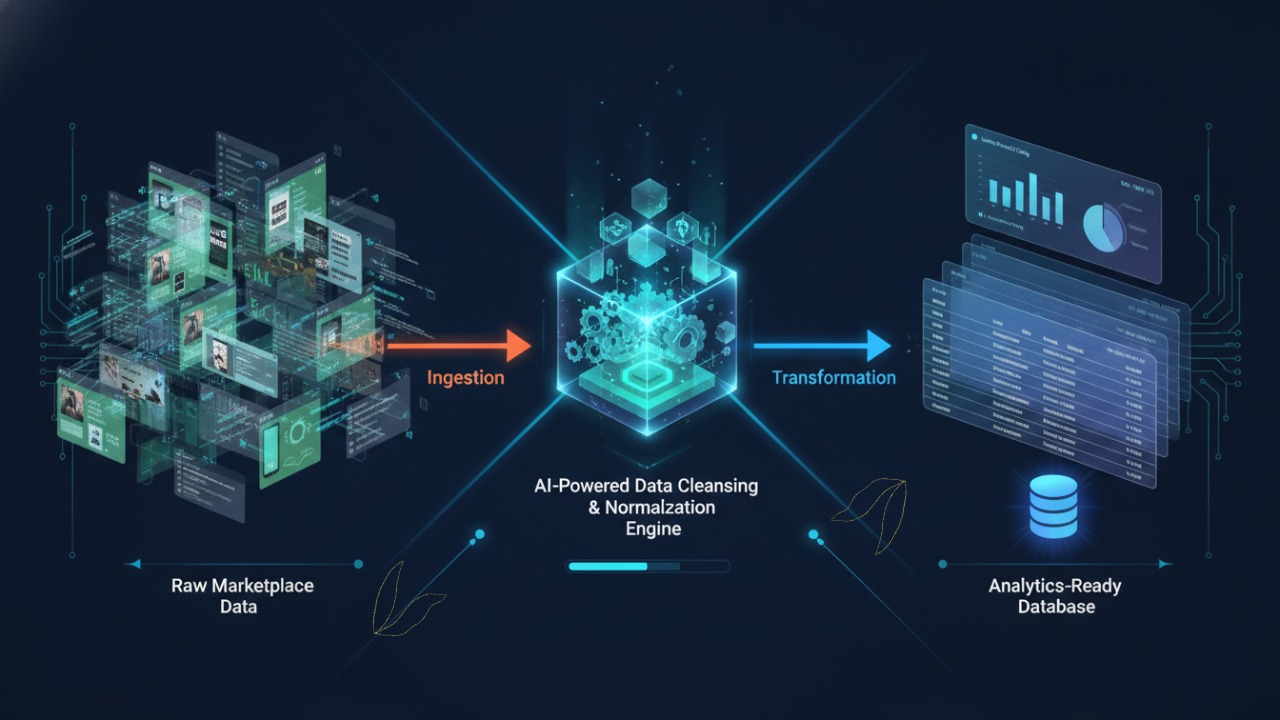
Visual data teams were struggling with one core issue. Ecommerce images are easy to collect but extremely hard to use at scale. Images are scattered across websites, stored in inconsistent formats, missing metadata, and delivered as raw files that require heavy cleanup before they can be used.
Teams spent more time fixing image data than working on analysis, modeling, or product decisions. Manual downloads, brittle scripts, and unstructured folders became operational bottlenecks. Crawl Feeds observed this repeatedly across ecommerce, research, and data engineering teams.
ImageHub was built to remove this friction.
Why are ecommerce images especially difficult to work with?
Unlike text or tabular data, images come with hidden complexity.
- File formats vary widely
- Resolution and aspect ratios are inconsistent
- Metadata is often missing or unreliable
- Folder structures carry implicit but undocumented meaning
- Duplicate images are common
Without structure, images cannot be reliably indexed, searched, or processed. This makes automation difficult and introduces risk into downstream workflows.
ImageHub was designed to treat images as structured data assets rather than loose files.
Why did Crawl Feeds decide to build a dedicated image platform?
Crawl Feeds already worked extensively with large-scale structured datasets. Over time, customers repeatedly raised the same challenge. They could access product data, pricing, and reviews, but visual data remained messy and expensive to operationalize.
Generic image download tools solved only one part of the problem. They fetched files but stopped there. Teams still had to clean, label, normalize, and document images themselves.
Crawl Feeds built ImageHub to handle the full lifecycle. From discovery to structured delivery.
What is ImageHub designed to do?
ImageHub is a platform for building structured ecommerce image datasets.
Its purpose is simple.
Take raw web images and convert them into consistent, metadata-rich datasets that teams can use immediately.
This includes:
- Discovering and collecting ecommerce images
- Normalizing formats and encodings
- Extracting and generating metadata
- Organizing images into predictable structures
- Delivering auditable exports
The goal is not just access. The goal is usability.
How does ImageHub handle image discovery and conversion?
ImageHub identifies image assets across ecommerce sources and standardizes them during ingestion.
This includes:
- Detecting file types and encodings
- Normalizing formats for consistency
- Preserving original image fidelity
By handling conversion early, ImageHub prevents downstream failures caused by incompatible or corrupted files.
How does ImageHub enrich image metadata?
Metadata is the foundation of ImageHub.
For every image, the platform can:
- Extract EXIF information
- Record dimensions and technical attributes
- Convert folder paths into structured category metadata
Optional enrichment can include OCR or computer vision labeling based on customer requirements.
This metadata-first approach allows images to be searched, filtered, analyzed, and integrated into production systems.
Why is auditability important for visual data teams?
Visual datasets often pass through multiple teams and systems. Without traceability, errors are hard to diagnose.
ImageHub maintains an audit trail for every transformation. Teams can see how an image was processed, what metadata was added, and how it was delivered.
This transparency is critical for research, analytics, and regulated environments where data provenance matters.
How does ImageHub deliver datasets?
ImageHub focuses on practical delivery formats that fit real workflows.
Supported outputs include:
- ZIP bundles with structured folders and metadata
- JSON files aligned to folder structures
- CSV exports for ingestion into analytics platforms or applications
- S3-compatible delivery options
These outputs are designed to plug directly into catalogs, machine learning pipelines, or internal tools.
Who is ImageHub built for?
ImageHub is built for teams that rely on visual data as part of their core operations.
This includes:
- Ecommerce and marketplace teams
- Data engineering teams
- Machine learning and computer vision teams
- Research organizations
- Agencies and analytics providers
If images are central to your workflow, ImageHub is designed to support scale without constant maintenance.
Why not build an in-house image pipeline?
Many teams attempt to manage image pipelines internally. Over time, these systems become fragile.
Common issues include:
- Scripts breaking when source structures change
- Inconsistent metadata across datasets
- Lack of documentation and auditability
- Growing technical debt
ImageHub replaces this with a managed, production-ready platform that evolves with changing data sources.
What ImageHub does not provide
ImageHub focuses on data preparation and delivery. It does not grant image usage rights. Users remain responsible for ensuring compliance with source terms and licensing requirements.
This clear separation helps teams manage legal responsibility without ambiguity.
How does ImageHub fit into the Crawl Feeds ecosystem?
Crawl Feeds delivers structured datasets across multiple domains. ImageHub extends this approach to visual data.
Together, they support:
- Text and web datasets
- Retail and ecommerce data
- News and content datasets
- Structured image datasets
All follow the same principles. Scale, consistency, and usability.
Learn more: Automated Image Dataset Generator: How ImageHub Simplifies AI Dataset Creation
Why did Crawl Feeds build ImageHub now?
Demand for visual data is accelerating. Ecommerce growth, AI adoption, and digital catalogs all depend on images.
Crawl Feeds built ImageHub to meet this demand with a platform designed for real-world production use.
ImageHub exists to make visual data reliable, structured, and ready for teams that cannot afford messy inputs.
Looking for a dataset?
Browse hundreds of pre-built datasets from CrawlFeeds — ecommerce, reviews, fashion, news, and more. Free samples on every dataset.
Browse datasets Custom data request